Saturday, November 27, 2010
Domain Owner Ship Page
"This post conforms my ownership of the site and that this site adheres to google adsense program policies and terms and conditions"
Major Advance Made On DNA Structure

ScienceDaily (May 4, 2005) — CORVALLIS, Ore. -- Oregon State University researchers have made significant new advances in determining the structure of all possible DNA sequences -- a discovery that in one sense takes up where Watson and Crick left off, after outlining in 1953 the double-helical structure of this biological blueprint for life.
ne of the fundamental problems in biochemistry is to predict the structure of a molecule from its sequence -- this has been referred to as the "Holy Grail" of protein chemistry.
Today, the OSU scientists announced in the Proceedings of the National Academy of Sciences that they have used X-ray crystallography to determine the three-dimensional structures of nearly all the possible sequences of a macromolecule, and thereby create a map of DNA structure.
As work of this type expands, it should be fundamentally important in explaining the actual biological function of genes - in particular, such issues as genetic "expression," DNA mutation and repair, and why some DNA structures are inherently prone to damage and mutation. Understanding DNA structure, the scientists say, is just as necessary as knowing gene sequence. The human genome project, with its detailed explanation of the genetic sequence of the entire human genome, is one side of the coin. The other side is understanding how the three-dimensional structure of different types of DNA are defined by those sequences, and, ultimately, how that defines biological function.
"There can be 400 million nucleotides in a human chromosome, but only about 10 percent of them actually code for genes," said Pui Shing Ho, professor and chair of the OSU Department of Biochemistry and Biophysics. "The other 90 percent of the nucleotides may play different roles, such as regulating gene expression, and they often do that through variations in DNA structure."
"Now, for the first time, we're really starting to see what the genome looks like in three dimensional reality, not just what the sequence of genes is," Ho said. "DNA is much more than just a string of letters, it's an actual structure that we have to explore if we ever hope to understand biological function. This is a significant step forward, a milestone in DNA structural biology."
In the early 1950s, two researchers at Cambridge University -- James Watson and Francis Crick -- made pioneering discoveries by proposing the double-helix structure of DNA, along with another research group in England about the same time. They later received the Nobel Prize for this breakthrough, which has been called the most important biological work of the past century and revolutionized the study of biochemistry. Some of the other early and profoundly important work in protein chemistry was done by Linus Pauling, an OSU alumnus and himself the recipient of two Nobel Prizes.
However, Watson and Crick actually identified only one structure of DNA, called B-DNA, when in fact there are many others -- one of which was discovered and another whose structure was solved at OSU in recent years -- that all have different effects on genetic function.
Aside from the genetic sequence that DNA encodes, the structure of the DNA itself can have profound biological effects, scientists now understand. Until now, there has been no reliable method to identify DNA structure from sequence, and learn more about its effects on biological function.
In their studies, the OSU scientists used X-ray examination of crystalline DNA to reconstruct exactly what the DNA looks like at the atomic level. By determining 63 of the 64 possible DNA sequences, they were able to ultimately determine the physical structure of the underlying DNA for all different types of sequences. Another important part of this study is the finding that the process of DNA crystallization does not distort its structure.
"Essentially, this is a proof of concept, a demonstration that this approach to studying DNA structure will work, and can ultimately be used to help understand biology," Ho said.
For instance, one of the unusual DNA structures called a Holliday junction, whose structure was co-solved at OSU about five years ago, apparently plays a key role in DNA's ability to repair itself -- a vital biological function.
A more fundamental understanding of DNA structure and its relationship to genetic sequences, researchers say, helps set the stage for applied advances in biology, biomedicine, genetic engineering, nanotechnology and other fields.
The recent work was supported by grants from the National Institutes of Health and the National Science Foundatio
DNA structure – Fine-tuning and optimization

Highly repetitive nucleotide sequences lack stability and mutate readily. However, a study involving the genomes of different organisms at the University of California suggests that codon usage in genes is actually designed to avoid the type of repetition that leads to unstable sequences! Further research indicates that codon usage in genes is also set up to maximize the accuracy of protein synthesis at the ribosome.
Furthermore, the components which comprise the nucleotides also appear to have been carefully chosen in view of enhanced performance. Nucleotides that form the strands of DNA are complex molecules which consist of both a phosphate moiety and a nucleobase (adenine, guanine, cytosine or thymine) joined to a five-carbon sugar (deoxyribose). In RNA, the five-carbon sugar ribose replaces deoxyribose.
The phosphate group of one nucleotide links to the deoxyribose unit of another to form the backbone of the DNA strand. The nucleobases form the ‘ladder rungs’ when the two strands align and twist to form the classical double-helix structure.
Scientists have long known that a myriad of sugars and numerous other nucleobases could have conceivably become part of the cell’s information storage medium (DNA). But why do the nucleotide subunits of DNA and RNA consist of those particular components? Phosphates can form bonds with two sugars simultaneously (called phosphodiester bonds) to bridge two nucleotides, while retaining a negative charge. This makes this chemical group perfectly suited to form a stable backbone for the DNA molecule. Other compounds can form bonds between two sugars but are not able to retain a negative charge. The negative charge on the phosphate group imparts the DNA backbone with stability, thus giving it protection from cleavage by reactive water molecules. Furthermore, the intrinsic nature of the phosphodiester bonds is also finely-tuned. For instance, the phophodiester linkage that bridges the ribose sugar of RNA could involve the 5’ OH of one ribose molecule with either the 2’ OH or 3’ OH of the adjacent ribose molecule. RNA exclusively makes use of 5’ to 3’ bonding. As it turns out, the 5’ to 3’ linkages impart far greater stability to the RNA molecule than does the 5’ to 2’ bonds.
Why do deoxyribose and ribose serve as the backbone constituents of DNA and RNA respectively? Both are five-carbon sugars which form five-membered rings. It is possible to make DNA analogues using a wide range of different sugars that contain four, five and six carbons that can form five- and six-membered rings. But these DNA variants possess undesirable properties as compared to DNA and RNA. For instance, some DNA analogues do not form double helices. Others do, but the nucleotide strands either interact too tightly or too weakly, or they display inappropriate selectivity in their associations. Furthermore, DNA analogues made from sugars that form 6-membered rings adopt too many structural conformations. In this event, it becomes exceptionally difficult for the cell’s machinery to properly execute DNA replication and transcription. Other research shows that deoxyribose uniquely provides the necessary space within the backbone region of the double helix of DNA to accommodate the large nucleobases. No other sugar fulfils this requirement.
DNA structure – An overview

DNA consists of two chainlike molecules (polynucleotides) that twist around each other to form the classic double-helix. The cell’s machinery forms polynucleotide chains by linking together four nucleotides. The nucleotides which are used to build DNA chains are adenosine (A), guanosine (G), cytidine (C), and thymidine (T). DNA houses the information required to make all the polypeptides used by the cell. The sequence of nucleotides in DNA strands (called a ‘gene’) specifies the sequence of amino acids in polypeptide chains.
Clearly a one-to-one relationship cannot exist between the four nucleotides of DNA and the twenty amino acids used to assemble polypeptides. The cell therefore uses groupings of three nucleotides (called ‘codons’) to specify twenty different amino acids. Each codon specifies an amino acid.
Because some codons are redundant, the amino acid sequence for a given polypeptide chain can be specified by several different nucleotide sequences. In fact, research has confirmed that the cell does not randomly make use of redundant codons to specify a particular amino acid in a polypeptide chain. Rather, there appears to be a delicate rationale behind codon usage in genes.
sexual reproduction and meiosis

DNA also replicates reliably in the process of meiosis, which happens before sex cells ( gametes ) are produced, but only half the normal number of chromosomes (and hence genes, and DNA) are distributed to each gamete. The sharing process in halving the number of chromosomes also includes elements of "scrambling" which introduce variation, so each gamete has a unique DNA content.
Meiosis
qmei1 qmei2 qmei3 qmei4 qmei5 qmei6
Firstly, chromosomes associate with
their "partners", then each replicates,
perhaps with exchange of genetic
material. Secondly, chromatids
separate - as in mitosis. qmei7 qmei8 qmei9
In meiosis, the nucleus divides twice to produce 4 nuclei, which then form into 4 genetically different sex cells (gametes), each containing half the number of chromosomes of the original cell (23 in human cells)
Therefore every organism produced as a result of sexual reproduction varies. However, the DNA built into the nucleus of a gamete may also be changed due to a random event called a mutation, which may alter or even prevent the normal activity of a gene inside cells. In this way a different form of the gene, called an allele , is produced, and will possibly be passed on to the next generation. Because each chromosome usually has a partner in the nucleus, the effect of a mutant allele may be hidden by the DNA of a normal allele of that gene which produces a normal characteristic.
DNA and NUCLEAR DIVISION
These 2 double strands form the 2 sections of chromosomes (called chromatids) that are easily seen when a cell is about to divide. In mitosis the chromosomes are then evenly distributed to different ends of the cell, ready to be incorporated into 2 new cells when the cell itself divides.
animation - mitosis
Mitosis
For clarity, only 2 pairs of chromosomes are shown in these diagrams
mit1 mit2 mit3 mit4 mit5
In mitosis, the nucleus divides once to produce 2 nuclei, which then form into 2 genetically identical "ordinary" cells, containing the same number of chromosomes as the original cell (46 in human cells)
Because of the reliability of the replication of DNA and mitosis, offspring resulting from asexual reproduction do not usually vary at all, which is the basis of taking cuttings, etc. Similarly, multicellular organisms consists of a harmonious population of identical cells derived from one initial cell, the fertilised egg or zygote. However, in some cases (about 1 in a million) there may be an error in the copying process; an incorrect copy of the DNA will be passed on to any (body) cells produced following cell division. This may be the cause of different types of cancer, which are associated with exposure to radiation or chemicals and viruses which damage DNA.
How DNA replicates

Understanding this goes a long way to explaining how nuclei divide in the process of mitosis , which results in identical copies of chromosomes being transferred during ordinary cell division.
Before a cell divides, its nucleus must divide. But before that happens, the chromosomes must have become double. So the first stage is that DNA which the chromosomes contain must replicate , i.e. become double, by making copies of itself.
The 2 strands of the DNA double helix can separate, under the influence of special enzymes in the nucleus, but each half remains attached along its length, like the 2 sections of a zip, because the sides of the strands are strongly joined.
In the diagrams below, write in the letters for the various bases (using the first few as a key). This should help you understand the results of the process.
Original DNA molecule Unzipping DNA
New bases being added 2 Double DNA strands
DNA replication
Each strand then acts as a basis for rebuilding the missing other strand from which it has been separated. It is said that each strand forms a template on which it reforms its complementary strand.
Enzymes within the nucleus match the appropriate base, which is already attached to strand side subunits, so that A fits against T, G against C, T against A and C against G, according to shape.
Other possibilities are not allowed, so the copying process is accurate in the vast majority of cases.
The result is that one double strand is converted into two identical double strands.
It is interesting to note that each "new" double strand is in fact half composed of a section of the previous DNA molecule, together with a completely new section built up from individual bases.
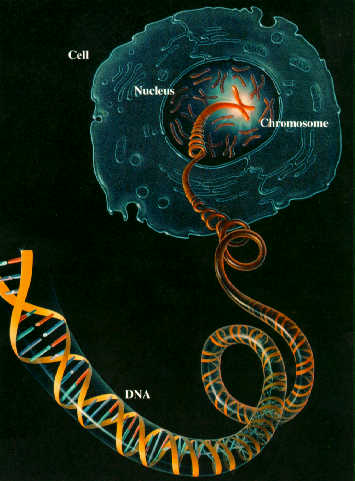
DNA and NUCLEAR DIVISION

A is an abbreviation for deoxyribonucleic acid, but it is usually known by its initials alone. DNA is found in practically all living organisms, and it is now known to carry genetic information from one cell to the next, and from one generation to the next. The units of inheritance, called genes, are actually sections of the DNA molecule.
Nuclei of the cells of higher organisms contain thread-like bodies called chromosomes, which consist of DNA, wrapped around proteins.
So understanding how the DNA molecule behaves inside cells helps explain how genetics works at the simplest level.
qnu16
In the nucleus of every normal cell of the human body there is over 1 metre of DNA, divided between 46 chromosomes.
DNA is a fascinating substance, because it can split into 2 halves, each of which can be built up to re-form the missing sections. It is, therefore, a molecule which is able to reproduce itself - essentially a characteristic of living organisms. For this reason, DNA is sometimes called the basis of life. It can also pass instructions out to the cytoplasm, in order to control the way the cell operates.
In the cell there are also other forms of a similar substance, RNA , ribonucleic acid, which are used to turn the genetic information into proteins that the cell needs. These proteins are mostly enzymes, used to control chemical activities in the cell, collectively known as its metabolism.
The DNA-Helix

The sugar-phosphate backbone is on the outside and the four different bases are on the inside of the DNA molecule.
The two strands of the double helix are anti-parallel, which means that they run in opposite directions.
The sugar-phosphate backbone is on the outside of the helix, and the bases are on the inside. The backbone can be thought of as the sides of a ladder, whereas the bases in the middle form the rungs of the ladder.
Each rung is composed of two base pairs. Either an adenine-thymine pair that form a two-hydrogen bond together, or a cytosine-guanine pair that form a three-hydrogen bond. The base pairing is thus restricted.
This restriction is essential when the DNA is being copied: the DNA-helix is first "unzipped" in two long stretches of sugar-phosphate backbone with a line of free bases sticking up from it, like the teeth of a comb. Each half will then be the template for a new, complementary strand. Biological machines inside the cell put the corresponding free bases onto the split molecule and also "proof-read" the result to find and correct any mistakes. After the doubling, this gives rise to two exact copies of the original DNA molecule.
The coding regions in the DNA strand, the genes, make up only a fraction of the total amount of DNA. The stretches that flank the coding regions are called introns, and consist of non-coding DNA. Introns were looked upon as junk in the early days. Today, biologists and geneticists believe that this non-coding DNA may be essential in order to expose the coding regions and to regulate how the genes are expressed.
We All Share the Same Building Blocks

DNA is a winning formula for packaging genetic material. Therefore almost all organisms – bacteria, plants, yeast and animals – carry genetic information encapsulated as DNA. One exception is some viruses that use RNA instead.
Different species need different amounts of DNA. Therefore the copying of the DNA that precedes cell division differs between organisms. For example, the DNA in E. coli bacteria is made up of 4 million base pairs and the whole genome is thus one millimeter long. The single-cell bacterium can copy its genome and divide into two cells once every 20 minutes.
The DNA of humans, on the other hand, is composed of approximately 3 billion base pairs, making up a total of almost a meter-long stretch of DNA in every cell in our bodies.
In order to fit, the DNA must be packaged in a very compact form. In E. coli the single circular DNA molecule is curled up in a condensed fashion, whereas the human DNA is packaged in 23 distinct chromosome pairs. Here the genetic material is tightly rolled up on structures called histones.
A New Biological Era
This knowledge of how genetic material is stored and copied has given rise to a new way of looking at and manipulating biological processes, called molecular biology. With the help of so-called restriction enzymes, molecules that cut the DNA at particular stretches, pieces of DNA can be cut out or inserted at different places.
In basic science, where you want to understand the role of all the different genes in humans and animals, new techniques have been developed. For one thing, it is now possible to make mice that are genetically modified and lack particular genes. By studying these animals scientists try to figure out what that gene may be used for in normal mice. This is called the knockout technique, since stretches of DNA have been taken away, or knocked out.
Scientists have also been able to insert new bits of DNA into cells that lack particular pieces of genes or whole genes. With this new DNA, the cell becomes capable of producing gene products it could not make before. The hope is that, in the future, diseases that arise due to the lack of a particular protein could be treated by this kind of gene therapy.
A Three-Helical Structure

The scientist Linus Pauling was eager to solve the mystery of the shape of DNA. In 1954 he became a Nobel Laureate in Chemistry for his ground-breaking work on chemical bonds and the structure of molecules and crystals. In early 1953 he had published a paper where he proposed a triple-helical structure for DNA. Watson and Crick had also previously worked out a three-helical model, in 1951. But their theory was wrong.
Their mistake was partly based on Watson having misremembered a talk by Rosalind Franklin where she reported that she had established the water content of DNA by using X-ray crystallographic methods. But Watson did not take notes, and remembered the numbers incorrectly.
Instead, it was Franklin's famous "photograph 51" that finally revealed the helical structure of DNA to Watson and Crick in 1953. This picture of DNA that had been crystallized under moist conditions shows a fuzzy X in the middle of the molecule, a pattern indicating a helical structure.
Solving the Puzzle
In the late 1940's, the members of the scientific community were aware that DNA was most likely the molecule of life, even though many were skeptical since it was so "simple." They also knew that DNA included different amounts of the four bases adenine, thymine, guanine and cytosine (usually abbreviated A, T, G and C), but nobody had the slightest idea of what the molecule might look like.
In order to solve the elusive structure of DNA, a couple of distinct pieces of information needed to be put together. One was that the phosphate backbone was on the outside with bases on the inside; another that the molecule was a double helix. It was also important to figure out that the two strands run in opposite directions and that the molecule had a specific base pairing.
As in the solving of other complex problems, the work of many people was needed to establish the full picture.
The Discovery of the Molecular Structure of DNA - The Double Helix

A Scientific Breakthrough
The sentence "This structure has novel features which are of considerable biological interest" may be one of science's most famous understatements. It appeared in April 1953 in the scientific paper where James Watson and Francis Crick presented the structure of the DNA-helix, the molecule that carries genetic information from one generation to the other.
Nine years later, in 1962, they shared the Nobel Prize in Physiology or Medicine with Maurice Wilkins, for solving one of the most important of all biological riddles. Half a century later, important new implications of this contribution to science are still coming to light.
What is DNA?
The work of many scientists paved the way for the exploration of DNA. Way back in 1868, almost a century before the Nobel Prize was awarded to Watson, Crick and Wilkins, a young Swiss physician named Friedrich Miescher, isolated something no one had ever seen before from the nuclei of cells. He called the compound "nuclein." This is today called nucleic acid, the "NA" in DNA (deoxyribo-nucleic-acid) and RNA (ribo-nucleic-acid).
Francis Crick and James Watson, 1953.
Photo: Cold Spring Harbor Laboratory Archives Maurice Wilkins.
Two years earlier, the Czech monk Gregor Mendel, had finished a series of experiments with peas. His observations turned out to be closely connected to the finding of nuclein. Mendel was able to show that certain traits in the peas, such as their shape or color, were inherited in different packages. These packages are what we now call genes.
For a long time the connection between nucleic acid and genes was not known. But in 1944 the American scientist Oswald Avery managed to transfer the ability to cause disease from one strain of bacteria to another. But not only that: the previously harmless bacteria could also pass the trait along to the next generation. What Avery had moved was nucleic acid. This proved that genes were made up of nucleic acid.
The structure of DNA

DNA is an example of a macromolecule, i.e. a large molecule with a special shape, which is built up from many smaller parts called sub-units .
If you could magnify part of a nucleus, you would see the DNA molecule looking like a twisted rope ladder - a double helix.
The two strands forming the sides of the ladder give it a strong yet flexible structure, which does not vary along its length.
Stretched between these are the "rungs" of the ladder, the parts of the DNA molecule which vary, and so the differences carry genetic information. These parts are made up of sections called bases, which fit together in pairs. Single section of DNA The 4 bases (so called because on their own they react with acids) are also usually known by their initials, as shown alongside:
A (adenine), paired with T (thymine)
and C (cytosine) paired with G (guanine).
Since T pairs with A, and G with C, there are actually 4 different possibilities at any position on a strand. The sequence or order of these bases in DNA is used to store and pass on the genetic information, in a similar way to computer data on a disc or tape.
If one strand of DNA has the base sequence C A T G A G C G C G A T , what will be the sequence on the other strand? > GTA CTC GCG CTA
Subscribe to:
Posts (Atom)